Query Expansion
A key application of query rewriting is increasing recall — that is, matching a larger set of relevant results. In extreme cases, increasing recall means the difference between returning some results and returning no results. More typically, query expansion casts a wider net for results that are relevant but don’t match the query terms exactly.
Overview
Query expansion broadens the query by introducing additional tokens or phrases. The search engine automatically rewrites the query to include them. For example, the query vp marketing becomes (vp OR “vice president”) marketing.
The main challenge for query expansion is obtaining those additional tokens and phrases. We also need to integrate query expansion into scoring and address the interface considerations that arise from query expansion.
Sources for Query Expansion Terms
We’ve covered spelling correction and stemming in previous posts, so we won’t revisit them here. In any case, they aren’t really query expansion. Spelling correction generally replaces the query rather than expanding it. Stemming is usually implemented by replacing tokens in queries and documents with their canonical forms, although it can also be implemented using query expansion.
Query expansion terms are typically abbreviations or synonyms.
Abbreviations
Abbreviations represent exactly the same meaning as the words they abbreviate, e.g., inc means incorporated. Our challenge is recognizing abbreviations in queries and documents.
Using a Dictionary
The simplest approach is to use a dictionary of abbreviations. There are many commercial and noncommercial dictionaries available, some intended for general-purpose language and others for specialized domains. We can also create our own. Dictionaries work well for abbreviations that are unambiguous, e.g., CEO meaning chief executive officer. We simply match strings, possibly in combination with stemming or lemmatization.
But abbreviations are often ambiguous. Does st mean street or saint? Without knowing the query or document context, we can’t be sure. Hence our dictionary has to be conservative to minimize the risk of matching abbreviations to the wrong words. We face a harsh trade-off between precision and recall.
Using Machine Learning
A more sophisticated approach is to model abbreviation recognition as a supervised machine learning problem. Instead of simply recognizing abbreviations as strings, we train a model using examples of abbreviations in context (e.g., the sequence of surrounding words), and we represent that context as components in a feature vector. This approach works better for identifying abbreviations in documents than in queries, since the former supply richer context.
How do we collect these examples? We could use an entirely manual process, annotating documents to find abbreviations and extracting them along with their contexts. But such an approach would be expensive and tedious.
A more practical alternative is to automatically identify potential abbreviations using patterns. For example, it’s common to introduce an abbreviation by parenthesizing it, e.g., gross domestic product (GDP). We can detect this and other patterns automatically. Pattern matching won’t catch all abbreviations, and it will also encounter false positives. But it’s certainly more scalable than a manual process.
Another way to identify abbreviations is to use unsupervised machine learning. We look for pairs of word or phrases that exhibit both surface similarity (e.g., matching first letters or one word being a prefix of the other) and semantic similarity. A popular tool for the latter is Word2vec: it maps tokens and phrases to a vector space such that the cosine of the angle between vectors reflects the semantic similarity inferred from the corpus. As with a supervised approach, this approach will both miss some abbreviations and introduce false positives.
Synonyms
Most of the techniques we’ve discussed for abbreviations apply to synonyms in general. We can identify synonyms using dictionaries, supervised learning, or unsupervised learning. As with abbreviations, we have to deal with the inherent ambiguity of language.
An important difference from abbreviations is that, since we can no longer rely on the surface similarity of abbreviations, we depend entirely on inferring semantic similarity. That makes the problem significantly harder, particularly for unsupervised approaches. We’re likely to encounter false positives from antonyms and other related words that aren’t synonyms.
Also, unlike abbreviations, synonyms rarely match the original term exactly. They may be more specific (e.g., computer -> laptop), more general (ipad -> tablet), or similar but not quite identical (e.g, web -> internet).
Hence, we not only need to discover and disambiguate synonyms; we also need to establish a similarity threshold. If we’re using Word2vec, we can require minimum cosine similarity.
Also, if we know the semantic relationship between the synonym and the original term, we can take it into account. For example, we can favor a synonym that is more specific than the original term, as opposed to one that is more general.
Scoring Results
Query expansion uses query rewriting to increase the number of search results. How do we design the scoring function to rank results that match because of query expansion?
The simplest approach is to treat matches from query expansion just like matches to the original query. This approach works for abbreviation matches that completely preserve the meaning of the original query terms — assuming that we don’t make any mistakes because of ambiguity. Synonym matches, however, may introduce subtle changes in meaning.
A more sophisticated approach is to apply a discount to matches from query expansion. This discount may be a constant, or it can reflect the expected change in meaning (e.g., a function of the cosine similarity). This approach, while heuristic, integrates well with hand-tuned scoring functions, such as those used in many Lucene-based search engines.
The best — or at least most principled — approach is to integrate query expansion into a machine learned ranking model using features (in the machine learning sense) that indicate whether a document matched the original query terms or terms introduced through query expansion. These features should also indicate whether the expansion was through an abbreviation or a synonym, the similarity of the synonym, etc.
Integrating query expansion into a machine-learned ranking model is a bit tricky. We can’t take full advantage of pre-existing training data from a system that hasn’t performed query expansion. Instead, we start with a heuristic model to collect training data (e.g., one of the previously discussed approaches) and then use that data to learn weights for query expansion features.
Interface Considerations
Query rewriting is always a gamble: it’s an attempt to do what the searcher meant, rather than what the searcher said. It’s important to mitigate this gamble through communication.
We can communicate that the search engine has performed query expansion by including an explicit message in the response. Here’s an example of a search for my name on Google:
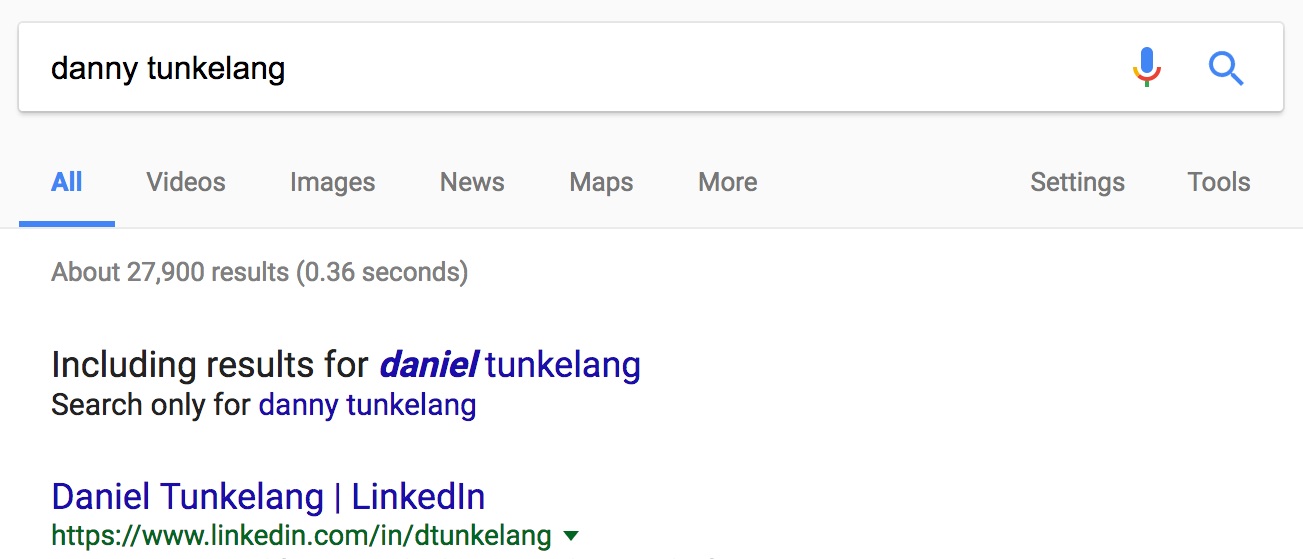
If the query expansion is aggressive, then it’s a good idea to inform the search and provide a one-click opportunity to undo it.
It’s even more valuable to communicate at the result level, by highlighting the expanded terms used to match each result. Here’s another example from Google: note how the second result bolds the term human-computer interaction that is an expansion of hci.
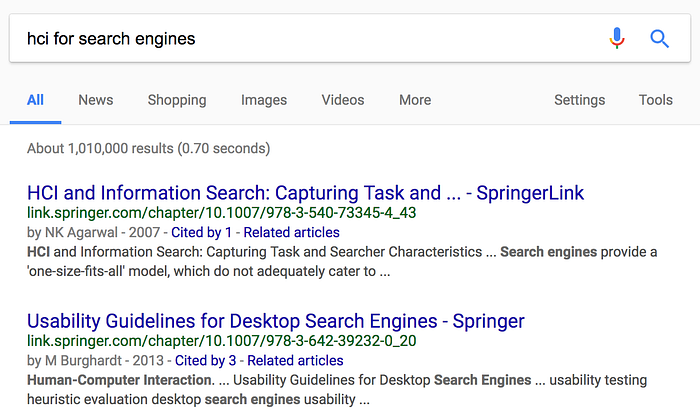
Summary
Query expansion is a valuable tool for increasing recall. Matching abbreviations and synonyms helps searchers find what they’re looking for, even when their language doesn’t match the results exactly. We can use off-the-shelf dictionaries or create our own, either manually or using machine learning. Beyond the challenge of identifying abbreviations and synonyms, we have to make changes to how we score and present results.
Query expansion is a lot of work, and it introduces complexity and risk. But the increased recall usually justifies the investment.
Previous: Query Rewriting: An Overview
Next: Query Relaxation

